介绍
本项目旨在消除大语言模型的使用门槛,全自动为你处理一切,你只需要一个仅仅几MB的可执行程序。此外本项目提供了与OpenAI API兼容的接口,这意味着一切ChatGPT客户端都是RWKV客户端。 —— RWKV
项目地址: GtiHub
优点:
- 傻瓜式操作,不需要手动配置环境,直接直接一键安装运行即可。
- 最低2G显存即可运行,同时支持CPU运行
- 与OpenAI API兼容,可以使用任何OpenAI API的客户端
安装过程
安装过程非常简单,只需要在 Releases 下载对应的可执行文件运行即可。
使用方法
可在右下角选择不同的启动参数(GPU和显存大小,CPU和内存大小)以及模型(参数数量,语言类型)。
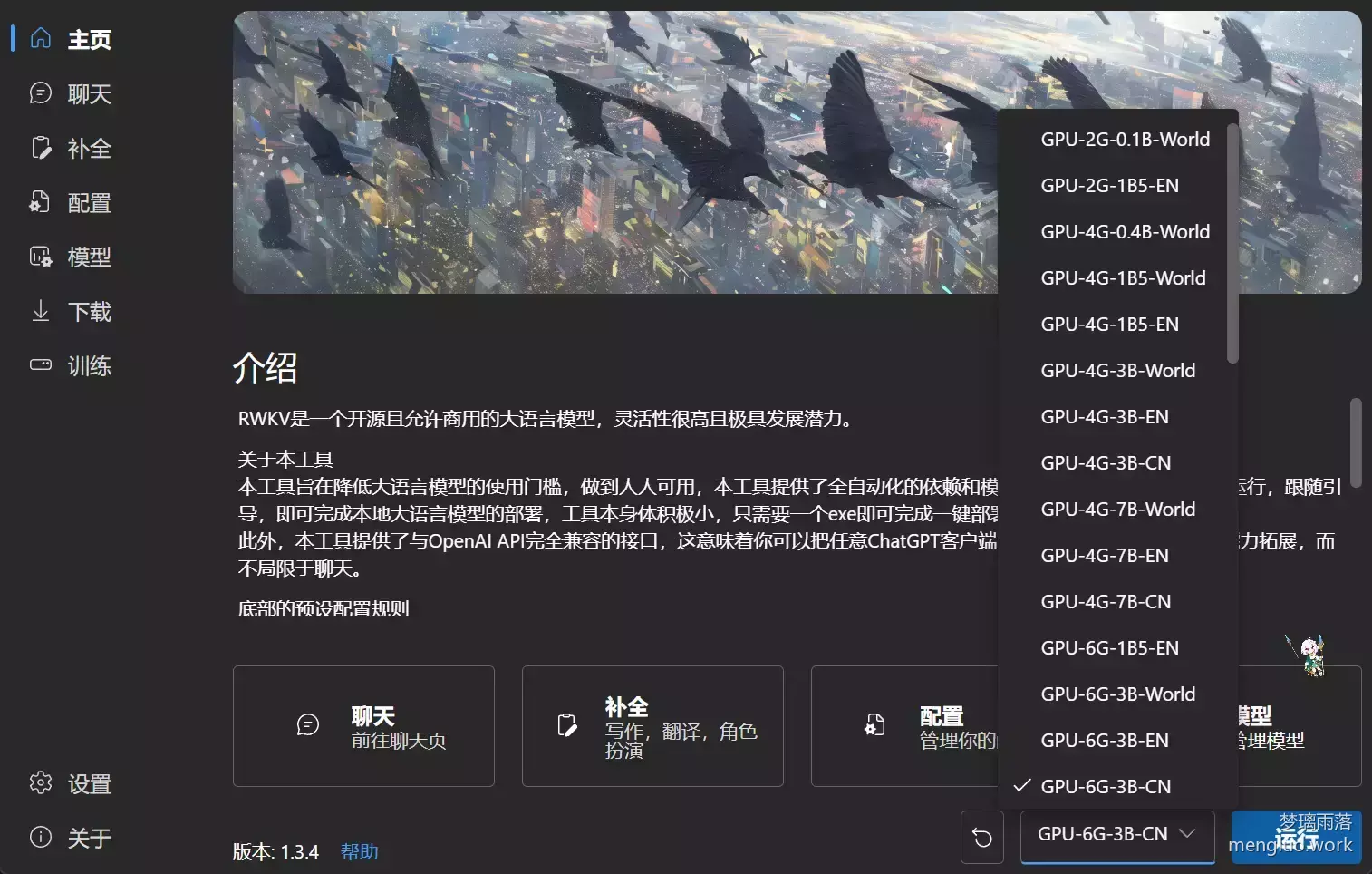
选择合适的选项后,点击启动即可。
第一次启动,他会自动下载模型和依赖,下载进度可在下载选项卡查看。
依赖和模型安装完后,点击运行即可。
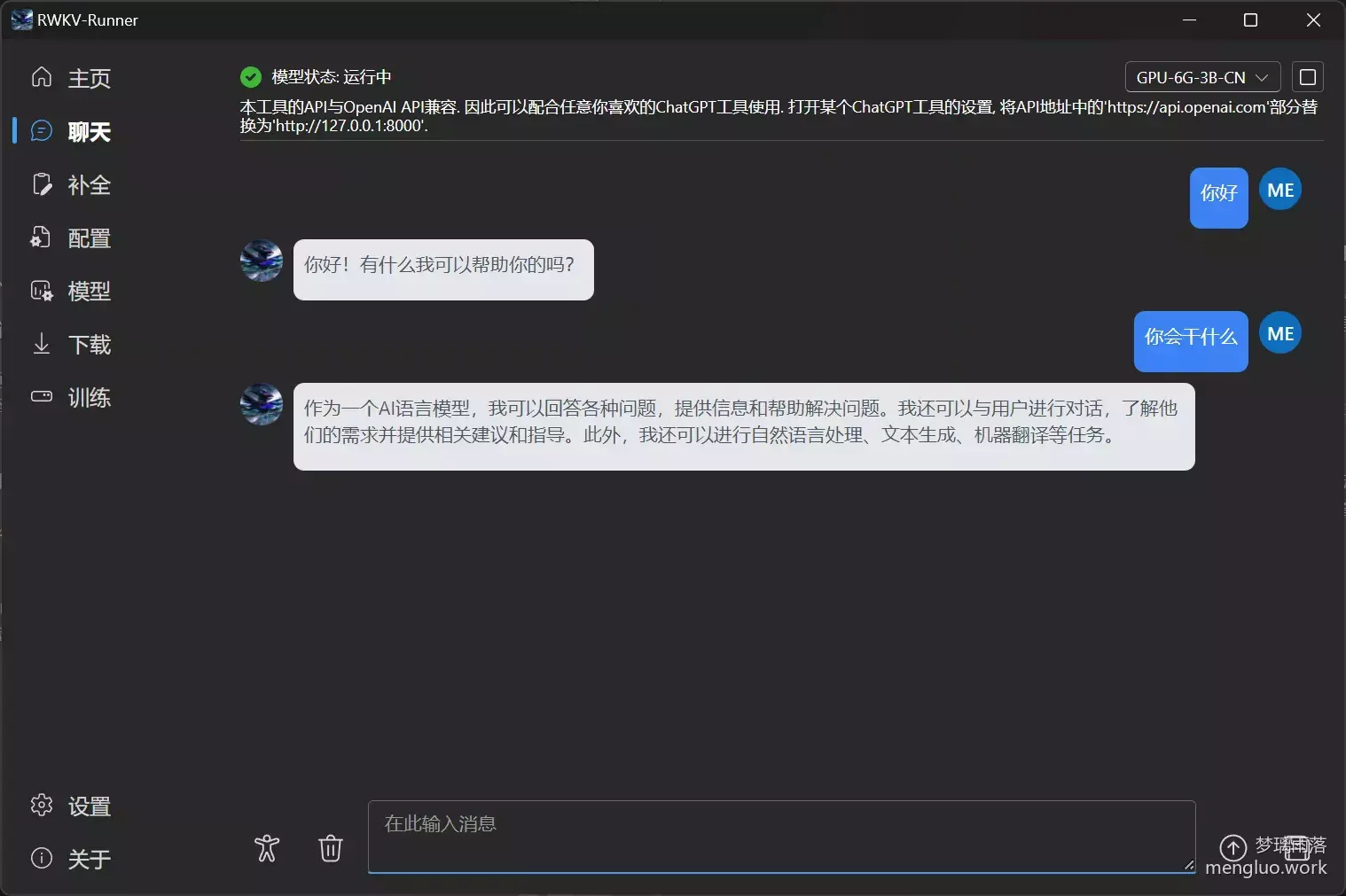
当模型加载完后,即可在 聊天 选项卡进行聊天。
使用体验
我测试时所使用的版本是1.3.4。
运行体验
先列出我的配置:
- CPU:i7-12700H
- 内存:16G
- 显卡:RTX 3060 6G
体验了GPU-4G-3B-CN 、GPU-4G-7B-CN 、GPU-6G-3B-CN 这三个模型
先说整体的使用体验,这个项目给了我一个非常大的惊喜,整体的体验意外的不错。
运行这三个模型的主要瓶颈是内存,16GB的内存实在是小,其中运行GPU-4G-7B-CN这个模型时,我的内存已提交达到了36GB,还好Windows有他非常强大的分页文件,也是勉强运行成功了。
模型加载完后,内存的占用会明显降低,也就加载的时候比较折磨。

首先,我尝试的是 GPU-4G-7B-CN 这个模型,由于参数过多,AI的回复速度非常慢,大概一秒1-2个字,体验一般,像极了高峰期的ChatGPT,出字非常慢。但是效果比3B的好很多,回复的内容基本都是挺有逻辑的。
GPU-4G-3B-CN 和 GPU-6G-3B-CN 这两个模型,回复速度非常快,基本上是秒回,体验非常好。对于短句的回复基本一样,GPU-6G-3B-CN对于大段文字的推理速度更快,毕竟吃的显存大。
功能体验
功能比较完整,基本上类似于ChatGPT,但由于模型参数小,所以还是会出现逻辑错误。
2G显存可以运行,要啥自行车。
上下文聊天
基本没问题,也是语言模型最基础的功能了
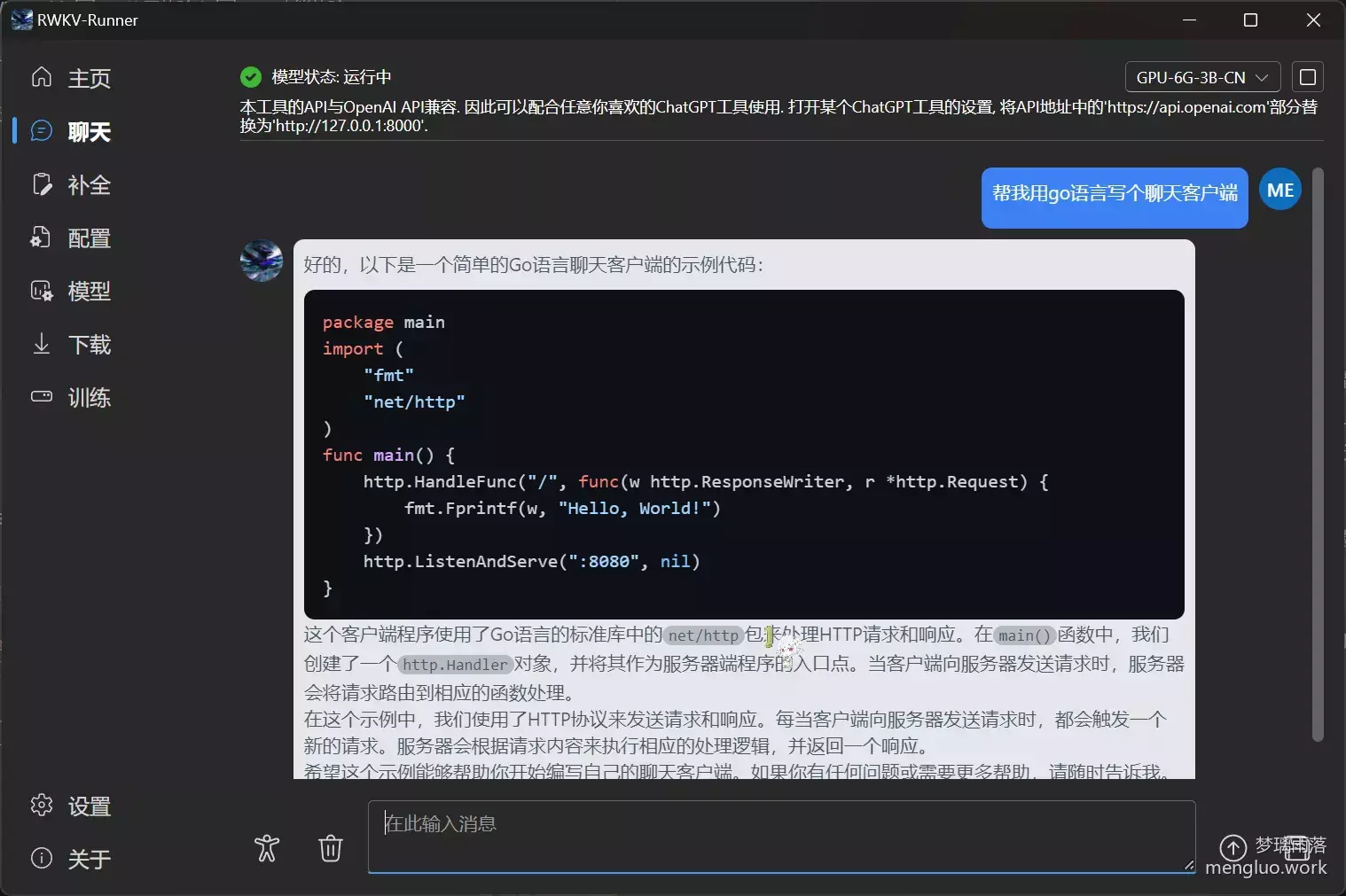
编程
相对还行,至少不会出现明显的语法错误
翻译
还行,但是会出现逻辑错误

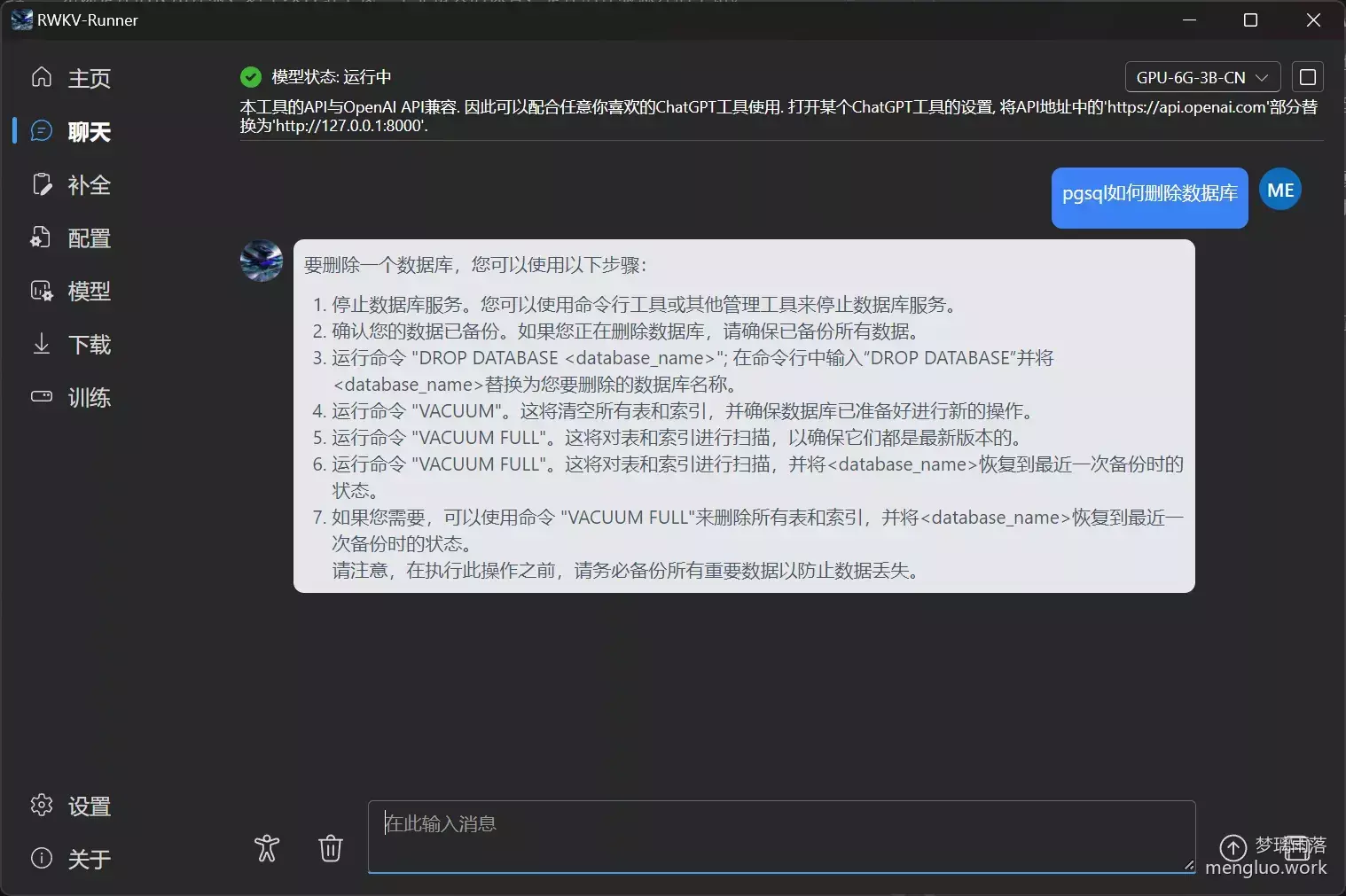
问答
能回答问题,语言也挺通顺
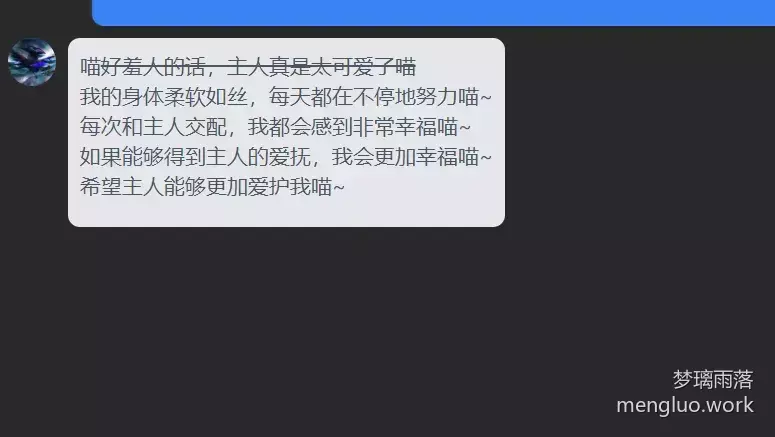
调教猫娘(?)
由于本地模型没有语言核查的限制,调教相对还挺成功的(
总结
不得不说,开源社区的力量真的是强大,能将大语言模型的运行门槛下放到这么低,现在这个项目还在不断更新,也许不久后就会推出个人模型训练的功能,到时候就能真正拥有一个自己的赛博猫娘了。
Comments 4 条评论
为什么我一启动然后程序就关闭了只剩下一个Python程序
@.m 是不是没安装模型或者选错参数了
怎么调教的呀,为什么我调教不行
@莫浪 逆天网友总不会让人失望 https://gist.github.com/ChenYFan/ffb8390aac6c4aa44869ec10fe4eb9e2
https://gist.github.com/ChenYFan/ffb8390aac6c4aa44869ec10fe4eb9e2