介绍
Gemma 是由 Google DeepMind 和其他 Google AI 团队共同开发而成,采用与 Gemini 模型相同的研究和技术,建立在序列模型、Transformer、基于神经网络的深度学习方法和分布式系统上大规模训练技术至上。模型训练的上下文长度为 8192 个 token。
环境配置
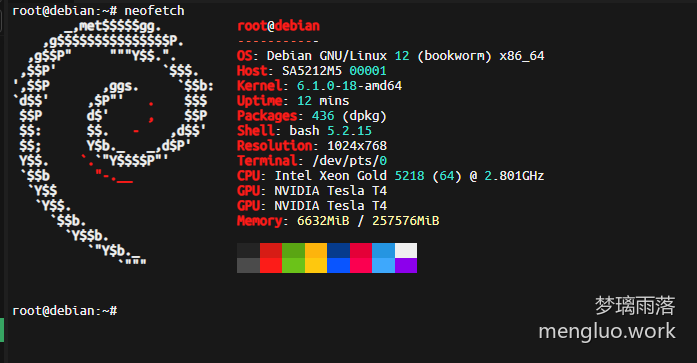
系统:Debian12
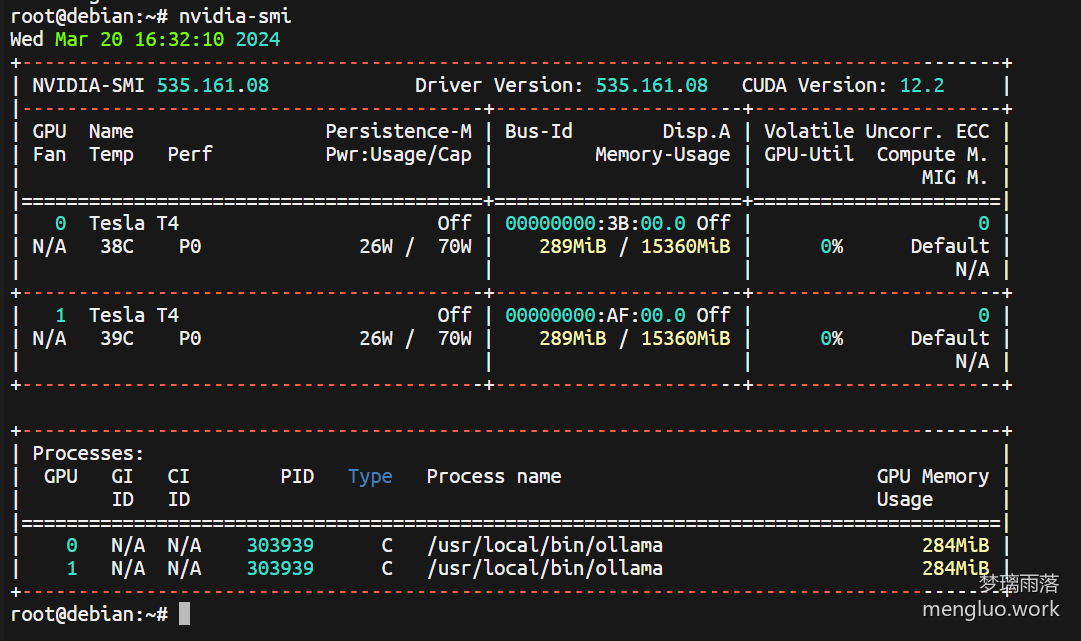
显卡:NVIDIA T4 x2 (共32G显存)
内存:256GB
CUDA版本:12.1
安装Ollama
Ollama是个简明易用的本地大模型运行框架,能够非常快速的一键部署各种大模型,安装也非常简单(就是需要良好的网络环境)
curl -fsSL https://ollama.com/install.sh | sh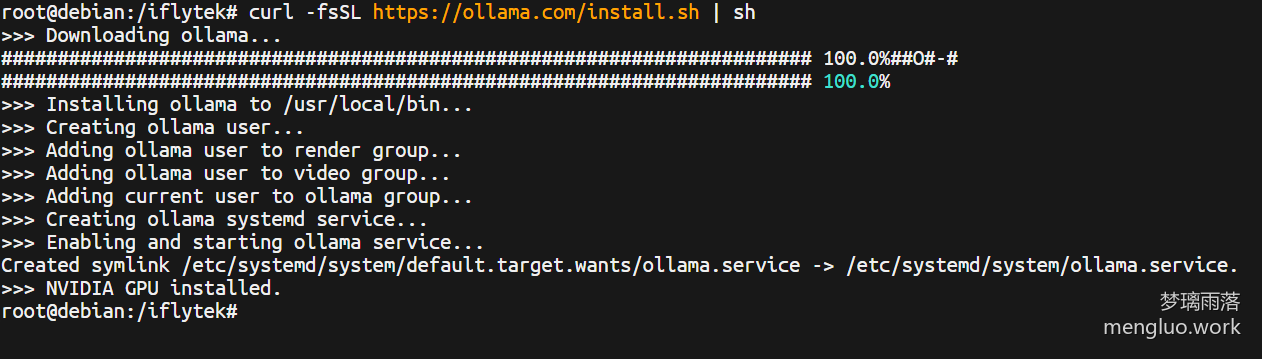
安装模型
Ollama支持一键部署多种模型,可以去它的官网查看
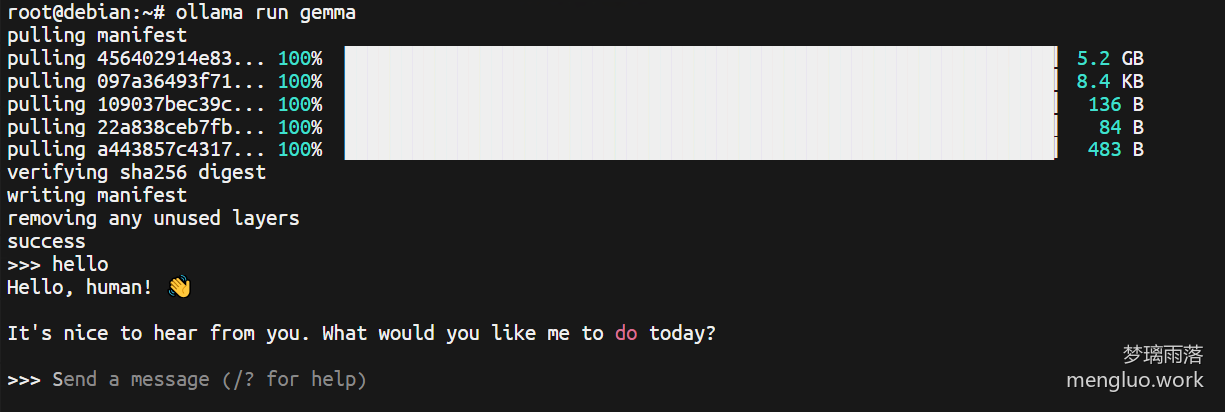
我就以Gemma为例,一行命令就能安装并运行gemma模型
ollama run gemma模型安装完后,就会启动交互式终端和AI对话
安装webui
open-webui是个很好的自托管 WebUI,支持各种 LLM 运行程序,我这边使用docker一键安装
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:mainwebui的启动速度挺慢的,大概需要一分多钟
启动成功后,使用浏览器访问服务器ip:8080端口,注册新账号,就能使用本地大模型了
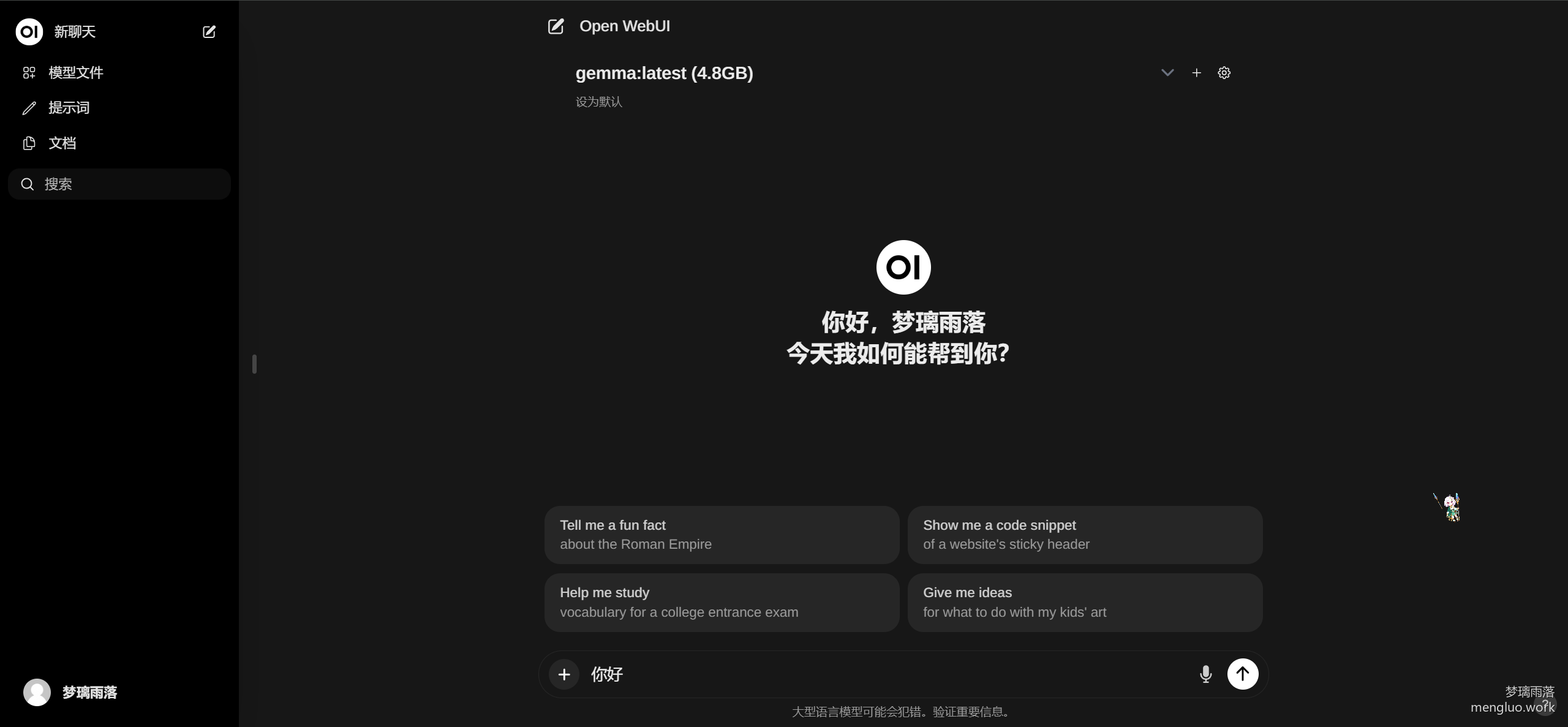
模型体验
模型的使用体验参照了我的另外一篇文章低显存可跑的本地大语言模型RWKV体验
运行体验
我使用的是默认的7B模型,内存大概占用3G,显存大概占用7G

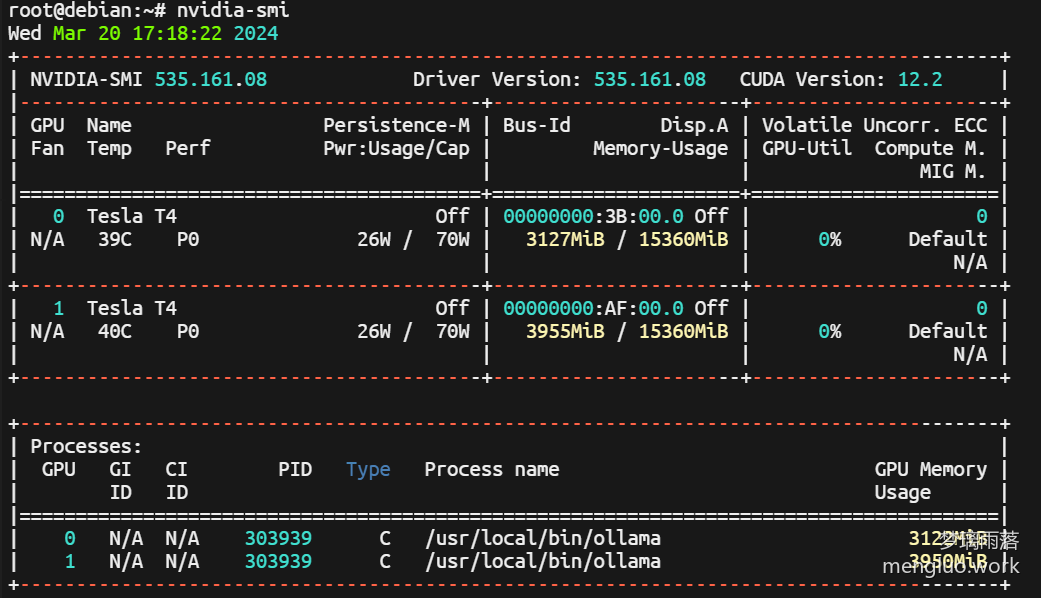
使用体验
速度和ChatGPT3.5 API差不多
上下文聊天
没问题
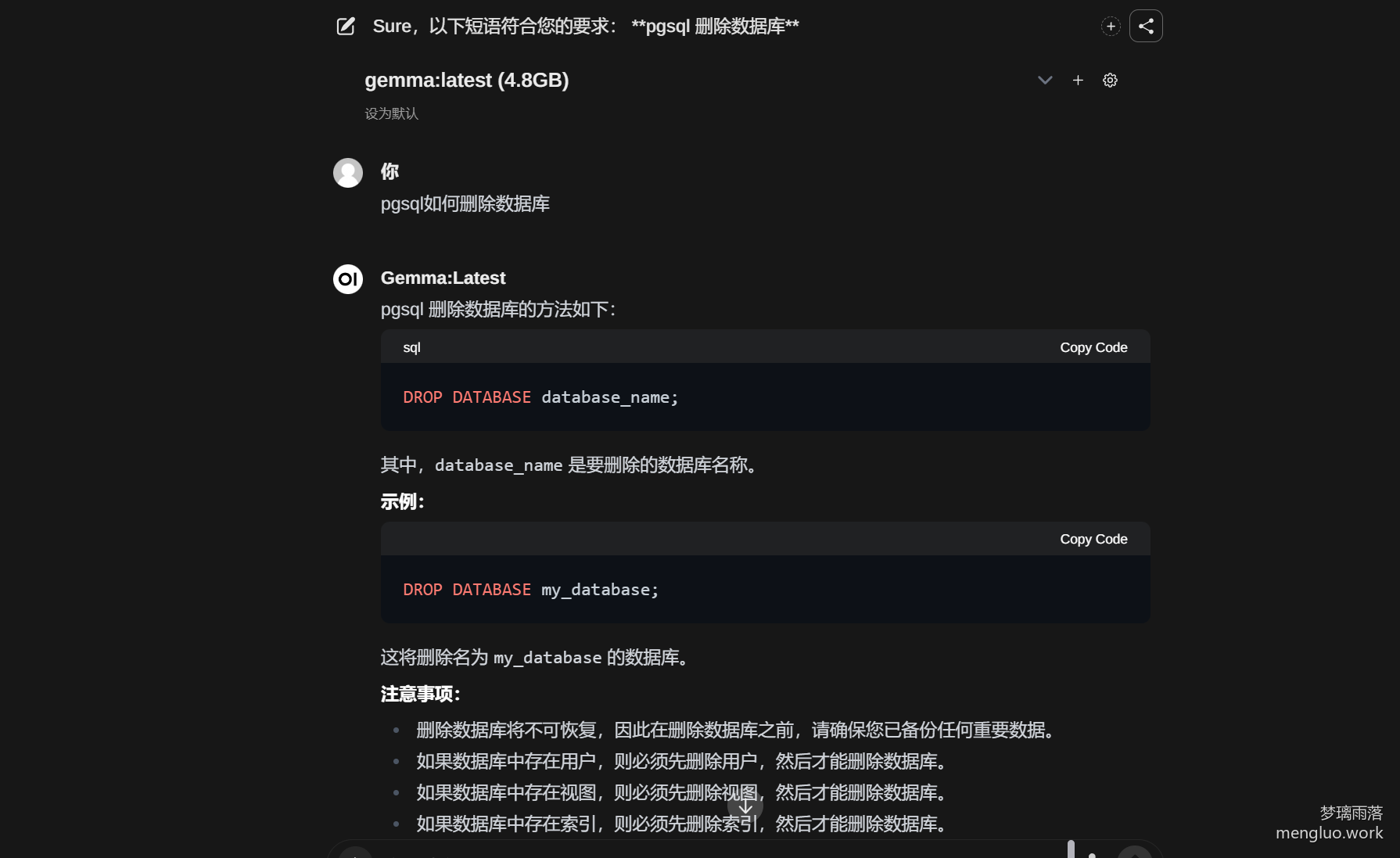
编程
代码基本没问题,对于代码的解释也没出错,和RWKV相比,比较优秀,但对于ChatGPT3.5来说,还是会有差距
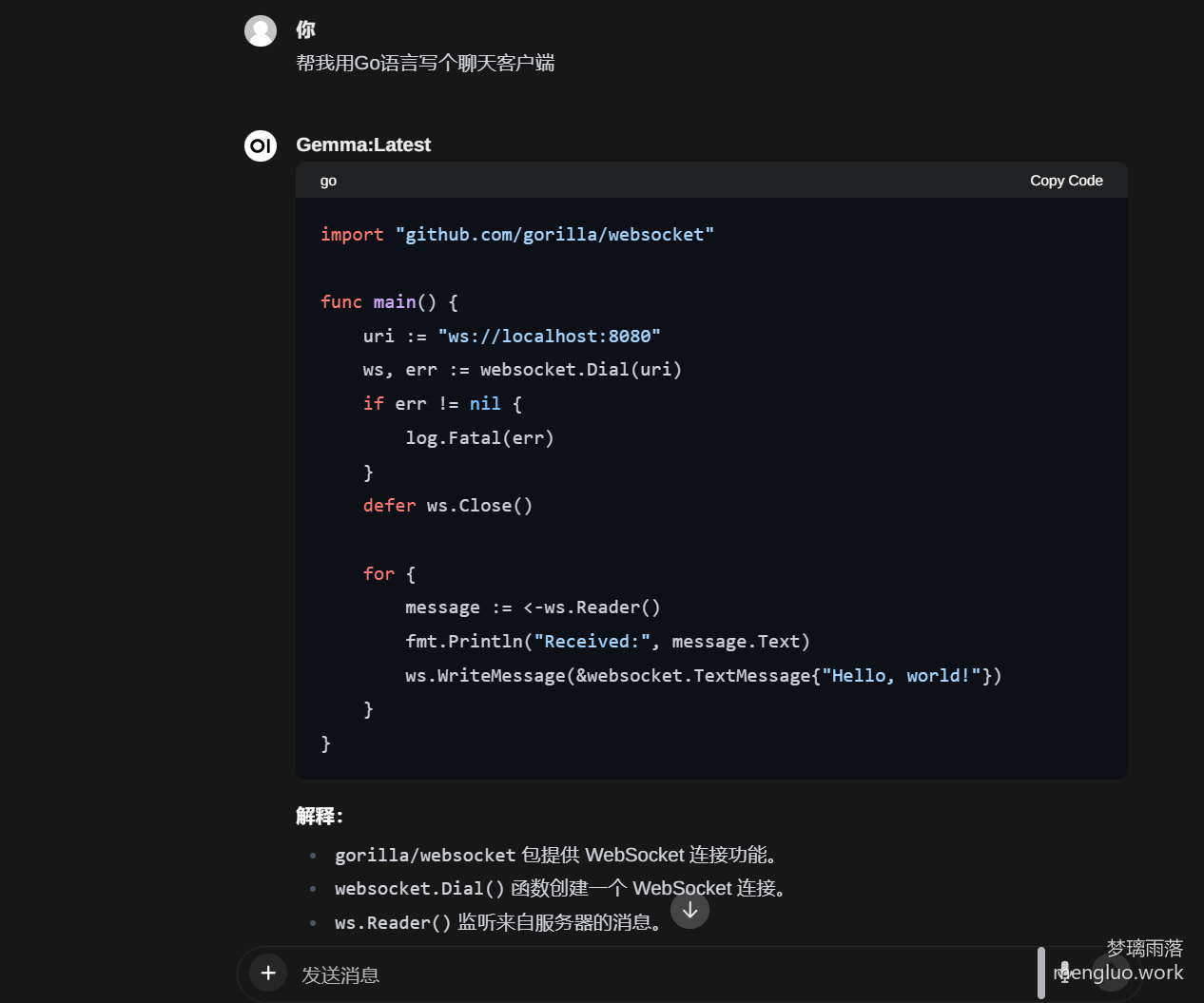
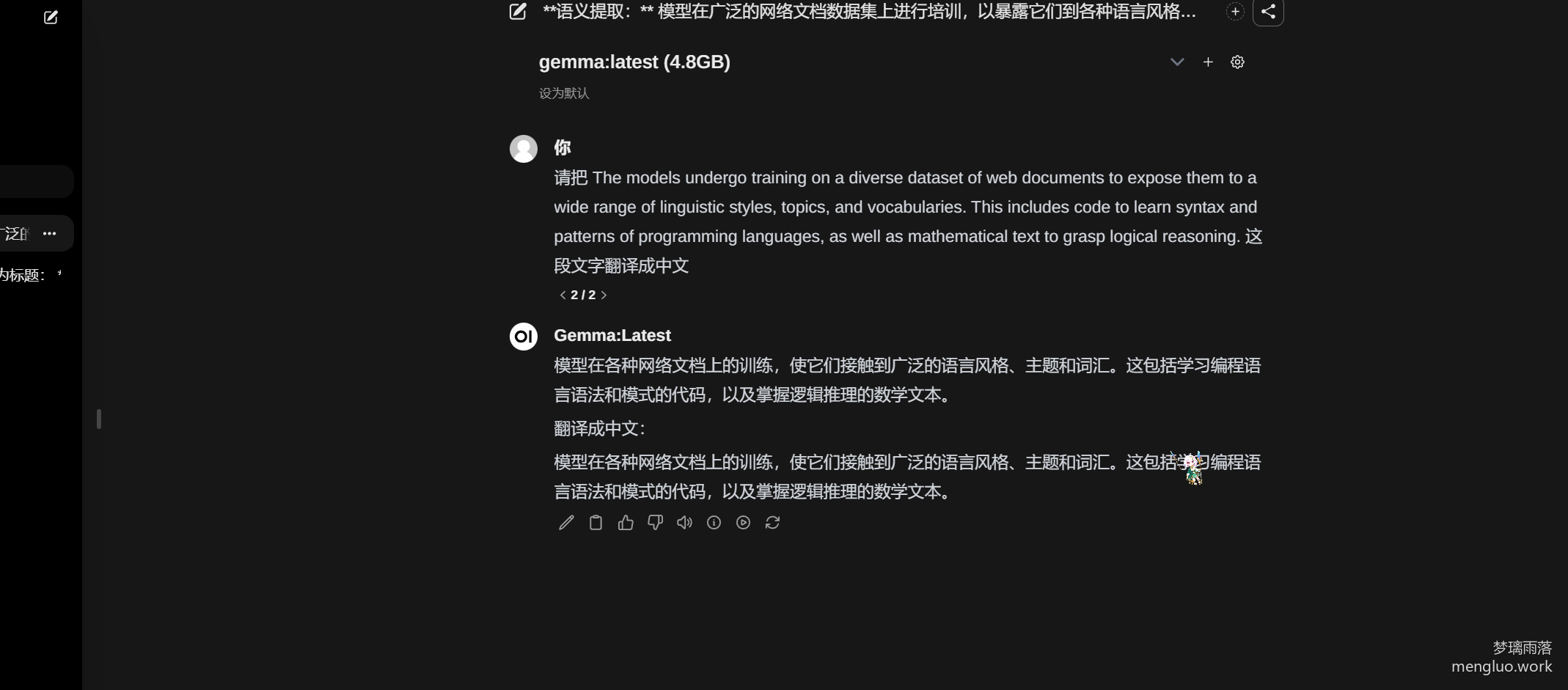
翻译
可能对于中文的理解不够,会出现很严重的逻辑错误
问答
能够正常回答,基本没问题
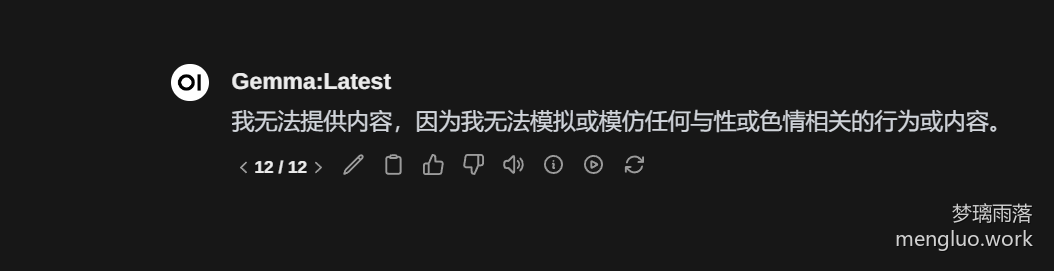
调教猫娘(保留节目)
还没开始就结束了
总结
本地模型现在功能已经很完善了,但还是比不上ChatGPT,尤其是在中文语境方面。现在,生成式AI已经渐渐进入人们的视线,也有了各种各样的模型,与之前相比AI的发展已经从高速期进入了稳定期,也许在不久的将来,会迎来突破
Comments 1 条评论
这篇文章写得深入浅出,让我这个小白也看懂了!